
Pull Request
Voir aussi Merge Request utilisé par GitLab.
Journaux liées à cette note :
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du mercredi 29 janvier 2025 à 16:29
Alexandre m'a fait remarquer que GitLab a activé par défaut une extension Markdown de génération automatique de TOC :
A table of contents is an unordered list that links to subheadings in the document. You can add a table of contents to issues, merge requests, and epics, but you can’t add one to notes or comments.
Add one of these tags on their own line to the description field of any of the supported content types:
[[_TOC_]] or [TOC]
- Markdown files.
- Wiki pages.
- Issues.
- Merge requests.
- Epics.
Je trouve cela excellent que cette extension Markdown soit supportée un peu partout, en particulier les issues, Merge Request… 👍️.
Cette fonctionnalité a été ajoutée en mars 2020 🫢 ! Comment j'ai pu passer à côté ?
GitHub permet d'afficher un TOC au niveau des README, mais je viens de vérifier, GitHub ne semble pas supporter cette extension TOC Markdown au niveau des issues… Pull Request…
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
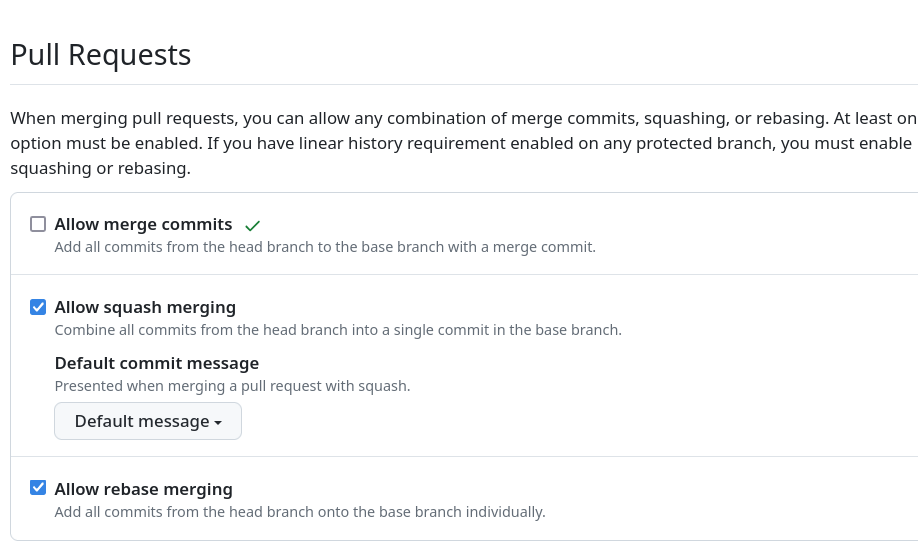
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
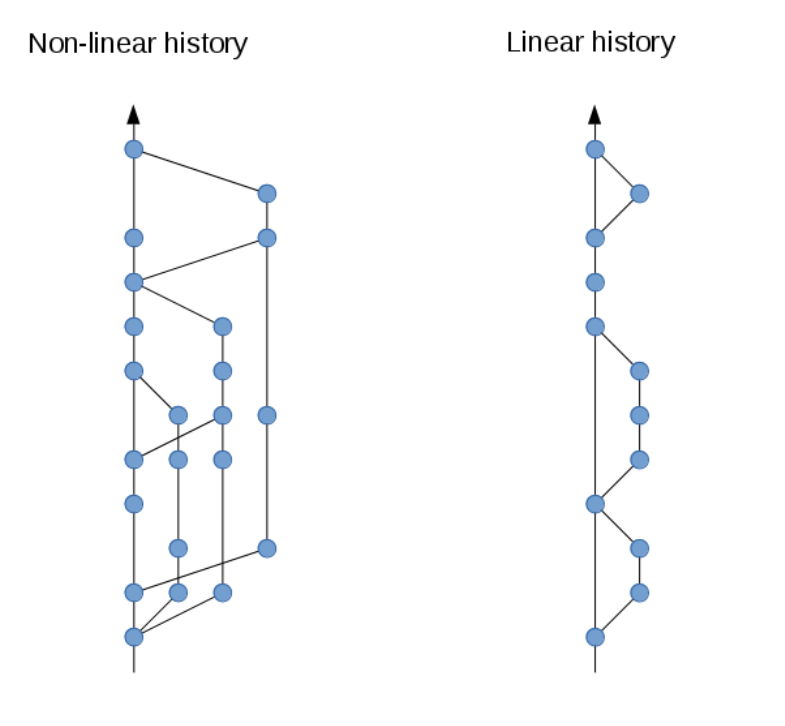
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.